
Machine learning models are only as good as the data they receive. Even the most advanced algorithms cannot perform well if the input data is messy, incomplete, or poorly structured. This is where Feature Engineering Techniques in Python become extremely important.
Feature engineering is one of the most critical steps in the machine learning pipeline. It involves transforming raw data into meaningful features that help machine learning models detect patterns more effectively. In real-world projects, the difference between a mediocre model and a highly accurate model often comes down to how well features are engineered.
For example, imagine you are building a house price prediction model. The raw dataset may contain information like address, number of rooms, and construction year. However, raw information alone may not help the model fully understand the relationships in the data. Through Feature Engineering Techniques in Python, we can create additional useful variables such as house age, neighborhood category, or price per square foot.
Professional data scientists spend a large portion of their time performing feature engineering because it significantly improves model performance. By applying the right Feature Engineering Techniques in Python, you can improve accuracy, reduce overfitting, and make machine learning models more reliable.
In this guide, you will learn the 10 most powerful Feature Engineering Techniques in Python that are commonly used in machine learning projects. Each technique will include explanations, examples, and practical Python code so that beginners can easily apply them in their own projects.
By the end of this tutorial, you will understand how to transform raw datasets into powerful features that help machine learning models perform better.
What is Feature Engineering in Machine Learning
Feature engineering is the process of transforming raw data into meaningful inputs that machine learning models can use to learn patterns.
In simple terms, features are the variables or attributes that describe the data. For example, in a dataset about houses, possible features might include:
- Number of bedrooms
- Square footage
- Location
- Construction year
However, raw datasets are rarely perfect. Many datasets contain missing values, inconsistent formats, or unnecessary information. This is why Feature Engineering Techniques in Python are necessary to prepare data before training machine learning models.
Feature engineering may include tasks such as:
- Handling missing data
- Creating new features from existing data
- Converting categorical data into numerical form
- Scaling numeric values
- Selecting the most relevant features
These transformations help machine learning algorithms understand the structure of the data more effectively.
Without proper feature engineering, even advanced machine learning models may struggle to identify meaningful patterns.
Why Feature Engineering is Important for Machine Learning
Many beginners believe that choosing the right machine learning algorithm is the most important part of building a model. In reality, feature engineering often has a greater impact on model performance.
There are several reasons why Feature Engineering Techniques in Python play such a crucial role in machine learning.
First, feature engineering helps models capture meaningful patterns in the data. Raw datasets often contain hidden relationships that become visible only after proper transformation.
Second, feature engineering can significantly improve model accuracy. By selecting and transforming relevant features, we provide better information for the model to learn from.
Third, feature engineering helps reduce overfitting. Removing irrelevant or redundant features prevents the model from memorizing noise instead of learning true patterns.
Finally, feature engineering makes machine learning models more efficient. When unnecessary features are removed, models train faster and require fewer computational resources.
Because of these benefits, mastering Feature Engineering Techniques in Python is essential for anyone working with machine learning.
Feature Engineering Workflow in Python
Before applying specific techniques, it is useful to understand the typical workflow used in machine learning projects.
A standard feature engineering workflow usually involves the following steps.
1. Data Cleaning
The first step is to clean the dataset by fixing missing values, correcting inconsistent data, and removing duplicates.
2. Feature Creation
New features can be created from existing data. For example, if a dataset contains a timestamp, we can extract the year, month, and day as separate features.
3. Feature Transformation
Data may need to be transformed to improve model learning. Examples include log transformations or normalization.
4. Feature Selection
Not all features are useful. Feature selection helps identify the most important variables and remove unnecessary ones.
5. Feature Scaling
Many machine learning algorithms perform better when numeric features are scaled to a similar range.
Python provides several powerful libraries that simplify these tasks.
The most commonly used libraries for Feature Engineering Techniques in Python include:
- Pandas
- NumPy
- Scikit-learn
Using these tools, data scientists can efficiently transform raw datasets into model-ready features.
Feature engineering is one of the most important steps in the overall machine learning workflow in Python, where raw data is prepared before training models.

Technique 1 — Handling Missing Values
Missing data is one of the most common problems in real-world datasets. Machine learning algorithms usually cannot handle missing values directly, so they must be addressed before training a model.
One of the most common Feature Engineering Techniques in Python is filling missing values using statistical measures.
The most common approaches include:
- Mean imputation
- Median imputation
- Mode imputation
For example, if a dataset contains missing values in an age column, we can replace them with the average age.
Python Example
import pandas as pd
df = pd.read_csv("data.csv")
df["age"].fillna(df["age"].mean(), inplace=True)
Median imputation is often preferred when the dataset contains outliers, because the median is less sensitive to extreme values.
Handling missing data correctly ensures that machine learning models receive complete and consistent information.
Handling missing values is one of the most important steps in data cleaning in Python for machine learning.
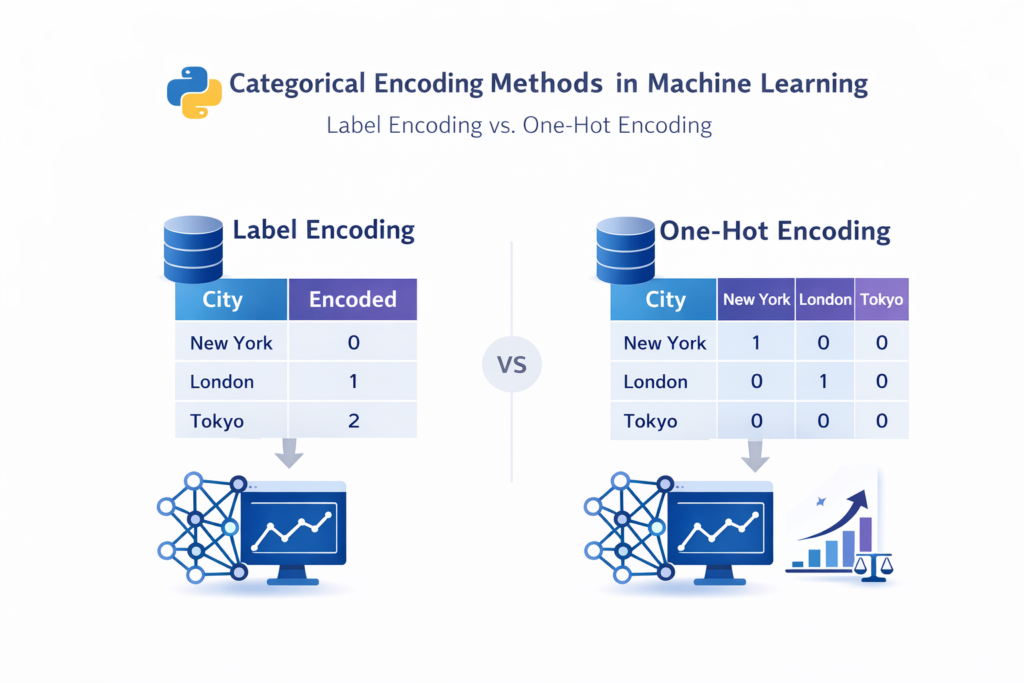
Technique 2 — Encoding Categorical Variables
Many datasets contain categorical values such as:
- city names
- product categories
- gender labels
Machine learning algorithms cannot process text-based categories directly. Therefore, these categories must be converted into numerical form.
Two common Feature Engineering Techniques in Python for handling categorical data are:
Label Encoding
Each category is assigned a numeric label.
Example:
Male → 0
Female → 1
One-Hot Encoding
Each category becomes a separate binary column.
Example:
| City | Karachi | Lahore | Islamabad |
|---|---|---|---|
| Karachi | 1 | 0 | 0 |
Python Example
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder()
encoded_data = encoder.fit_transform(df[["city"]])
When One-Hot Encoding Can Be Problematic
If a feature contains hundreds of categories, one-hot encoding may create too many columns, increasing dataset dimensionality. In such cases, alternative methods like target encoding may be more efficient.
Technique 3 — Feature Scaling
Different features in a dataset may have very different ranges.
For example:
- Age: 20–60
- Salary: 30,000–200,000
Machine learning algorithms that rely on distance calculations may perform poorly if feature scales differ significantly.
Python libraries such as Scikit-learn preprocessing tools provide powerful functions for scaling and transforming data before training machine learning models.
Feature scaling is one of the most widely used Feature Engineering Techniques in Python.
Two common scaling methods include:
Standardization
Standardization transforms data so that it has a mean of zero and a standard deviation of one.
Min-Max Scaling
This method rescales values to a range between 0 and 1.
Python Example
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaled_data = scaler.fit_transform(df[["salary"]])
When Scaling is Not Necessary
Tree-based algorithms such as:
- Decision Trees
- Random Forest
- Gradient Boosting
do not require feature scaling because they split data based on thresholds rather than distances.
Technique 4 — Creating New Features
One of the most powerful Feature Engineering Techniques in Python is creating new features from existing data. Many real-world datasets contain hidden information that can be extracted to improve machine learning models.
Instead of relying only on raw data columns, data scientists often generate additional features that capture meaningful patterns. These new variables can significantly improve the performance of machine learning models.
For example, imagine a dataset containing a date column showing when a transaction occurred. Instead of using the date directly, we can extract several useful features such as:
- Year
- Month
- Day
- Day of the week
These additional variables can help the model detect seasonal or time-based patterns.
Another common example is calculating age from birth year or computing price per square foot in real estate datasets.
Creating useful derived features is one of the most practical Feature Engineering Techniques in Python because it helps models understand relationships that are not immediately obvious in the raw dataset.
Python Example
import pandas as pd
df["year"] = pd.to_datetime(df["date"]).dt.year
df["month"] = pd.to_datetime(df["date"]).dt.month
df["day"] = pd.to_datetime(df["date"]).dt.day
These additional columns give the machine learning model more information to learn from.
Feature creation is often driven by domain knowledge, meaning that understanding the problem domain can help identify valuable new features.
Technique 5 — Feature Transformation
Another important category of Feature Engineering Techniques in Python involves transforming existing numerical features.
In many datasets, numeric values may not follow a normal distribution. Skewed data can negatively affect machine learning algorithms, especially linear models.
Feature transformation techniques help reshape the distribution of data so that models can learn patterns more effectively.
Some common transformation methods include:
- Log transformation
- Square root transformation
- Power transformation
These techniques reduce the impact of extreme values and make the dataset more balanced.
For example, income or transaction data often contains a few extremely large values that create skewed distributions. Applying a log transformation can make the data more suitable for machine learning models.
Python Example
import numpy as np
df["log_income"] = np.log(df["income"])
After transformation, the distribution of values becomes more balanced, which often improves model performance.
Feature transformation is particularly useful when working with financial datasets, sales data, or population statistics.
Technique 6 — Binning (Discretization)
Binning, also known as discretization, is another useful technique among Feature Engineering Techniques in Python.
This technique converts continuous numerical values into grouped categories. Instead of using precise numeric values, the data is divided into ranges.
For example, a dataset containing age values can be grouped into categories such as:
- 0–18 → Young
- 19–40 → Adult
- 41–60 → Middle Age
- 60+ → Senior
This transformation can help machine learning models identify patterns that depend on ranges rather than exact numbers.
Binning is particularly helpful when:
- The relationship between variables is non-linear
- Exact numeric precision is not important
- Simplifying the dataset improves interpretability
Python Example
df["age_group"] = pd.cut(df["age"], bins=[0,18,40,60,100],
labels=["Young","Adult","Middle Age","Senior"])
By grouping data into categories, binning can reduce noise and make patterns easier for machine learning models to detect.
Technique 7 — Handling Outliers
Outliers are extreme values that differ significantly from the rest of the dataset. These values can distort machine learning models and reduce prediction accuracy.
Handling outliers is an essential part of many Feature Engineering Techniques in Python, especially when working with real-world datasets.
For example, consider a dataset of house prices where most homes cost between $100,000 and $500,000. If a few entries contain values like $10,000,000 due to data errors, these extreme values may negatively influence the model.
Two common methods are used to detect and manage outliers.
Z-Score Method
This method measures how far a value is from the mean in terms of standard deviations.
If the absolute Z-score is greater than a certain threshold (usually 3), the value may be considered an outlier.
IQR Method (Interquartile Range)
The IQR method identifies outliers by measuring the spread between the first and third quartiles.
Values outside this range may be treated as outliers.
Python Example
Q1 = df["price"].quantile(0.25)
Q3 = df["price"].quantile(0.75)
IQR = Q3 - Q1
df = df[(df["price"] >= Q1 - 1.5 * IQR) &
(df["price"] <= Q3 + 1.5 * IQR)]
Removing or adjusting outliers helps prevent machine learning models from being overly influenced by unusual data points.
Properly handling outliers is a crucial step in applying Feature Engineering Techniques in Python to improve model stability and accuracy.
Technique 8 — Feature Selection
Not all features in a dataset are useful for machine learning models. Some variables may contain little information, while others may introduce noise that reduces model performance. This is why feature selection is an important step in applying Feature Engineering Techniques in Python.
Feature selection helps identify the most relevant features while removing unnecessary ones. This improves model accuracy and reduces computational cost.
There are several common methods used for feature selection.
Correlation Analysis
Correlation analysis measures the relationship between features and the target variable. Features with very low correlation may not contribute much to model performance.
SelectKBest
This method selects the top K most important features based on statistical tests.
Recursive Feature Elimination (RFE)
RFE works by repeatedly training a model and removing the least important features until the optimal set is found.
Python Example
from sklearn.feature_selection import SelectKBest, f_classif
selector = SelectKBest(score_func=f_classif, k=5)
selected_features = selector.fit_transform(X, y)
Feature selection is particularly useful when working with datasets that contain many columns.
Removing unnecessary variables allows machine learning models to focus only on the most informative features.
Technique 9 — Polynomial Features
Some machine learning models assume that relationships between variables are linear. However, many real-world relationships are non-linear. Polynomial features help capture these complex relationships.
Polynomial feature generation is another powerful method within Feature Engineering Techniques in Python. It creates new features by combining existing variables with mathematical powers.
For example, if a dataset contains a feature x, polynomial transformation may create additional features such as:
- x²
- x³
- x¹x²
These additional variables allow models to capture curved relationships between inputs and outputs.
Python Example
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2)
poly_features = poly.fit_transform(X)
When to Use Polynomial Features
Polynomial features are useful when:
- Relationships between variables are non-linear
- Linear models are being used
- Dataset size is relatively small
When Not to Use Polynomial Features
Polynomial features can significantly increase the number of variables in a dataset. This may lead to overfitting or computational inefficiency if the dataset already contains many features.
Because of this, polynomial transformations should be applied carefully.
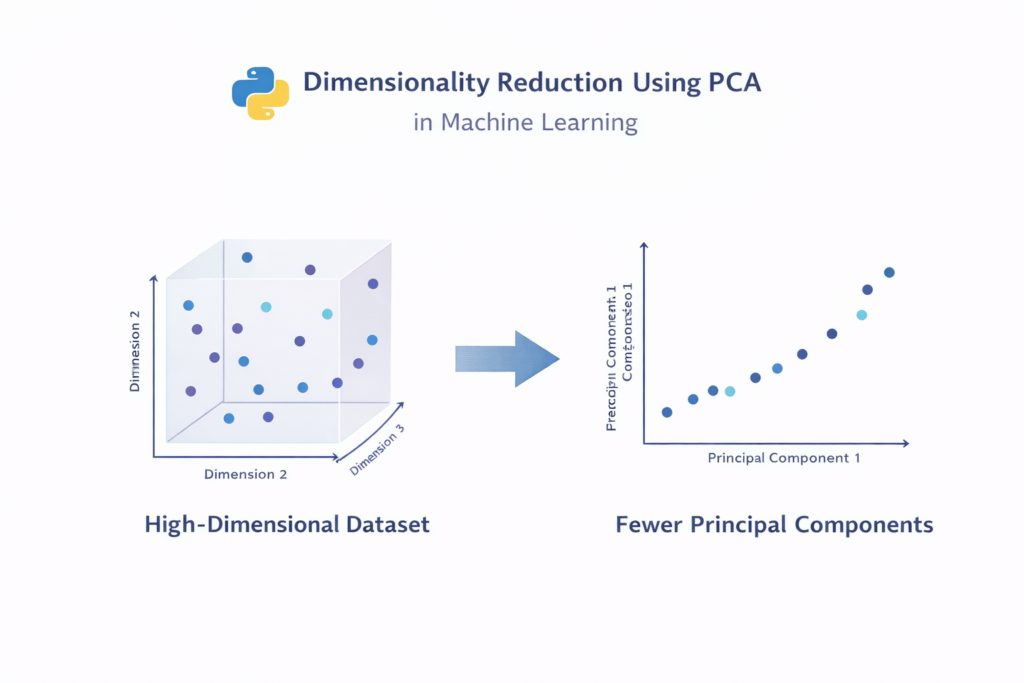
Technique 10 — Dimensionality Reduction
High-dimensional datasets often contain hundreds or even thousands of features. Too many features can make machine learning models slower and more complex.
Dimensionality reduction is one of the most advanced Feature Engineering Techniques in Python used to simplify datasets while preserving important information.
One of the most widely used dimensionality reduction methods is Principal Component Analysis (PCA).
PCA works by transforming the original features into a smaller set of new variables called principal components. These components capture most of the important variance in the dataset.
Python Example
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
reduced_data = pca.fit_transform(X)
When to Use PCA
Dimensionality reduction is helpful when:
- The dataset contains many features
- Training time is very high
- Visualization of high-dimensional data is needed
When Not to Use PCA
PCA may reduce interpretability because the resulting components are combinations of multiple original features.
Therefore, PCA should be used carefully in projects where feature interpretation is important.
One of the most widely used dimensionality reduction methods is Principal Component Analysis (PCA), which helps reduce dataset complexity while preserving important information.
Complete Feature Engineering Example in Python
To understand how Feature Engineering Techniques in Python work together, let’s look at a simplified workflow.
Step 1: Load Dataset
import pandas as pd
df = pd.read_csv("data.csv")
Step 2: Handle Missing Values
df.fillna(df.mean(), inplace=True)
Step 3: Encode Categorical Data
df = pd.get_dummies(df, columns=["city"])
Step 4: Scale Features
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaled_features = scaler.fit_transform(df)
Step 5: Train Machine Learning Model
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
This example demonstrates how different Feature Engineering Techniques in Python work together before training a machine learning model.
Before training a model, it is important to perform a train test split in Python to properly evaluate model performance.
Common Feature Engineering Mistakes
Even though feature engineering is powerful, beginners often make several mistakes that reduce model performance.
Data Leakage
Data leakage occurs when information from the test dataset accidentally influences the training process.
For example, scaling the entire dataset before splitting it into training and testing sets can lead to misleading results.
Correct workflow:
Split dataset → scale training data → apply same transformation to test data.
Creating Too Many Features
Adding too many features can increase model complexity and lead to overfitting.
Ignoring Domain Knowledge
Understanding the problem domain is extremely important for creating meaningful features.
Using One-Hot Encoding for High Cardinality Features
If a categorical variable contains hundreds of categories, one-hot encoding may produce too many columns.
Avoiding these mistakes helps ensure that Feature Engineering Techniques in Python improve model performance rather than harming it.
Poor feature selection can lead to problems such as overfitting vs underfitting in machine learning, which reduces model reliability.
Best Python Libraries for Feature Engineering
Python provides many powerful libraries that simplify feature engineering tasks.
Some of the most popular libraries include:
Pandas
Pandas is widely used for data manipulation and feature creation.
The Pandas data manipulation library is widely used for cleaning, transforming, and preparing datasets in Python.
NumPy
NumPy provides fast numerical operations for transforming datasets.
Scikit-learn
Scikit-learn includes many built-in tools for feature scaling, selection, and transformation.
Featuretools
Featuretools is an advanced library that automates feature engineering.
Using these libraries makes it much easier to apply Feature Engineering Techniques in Python in real-world machine learning projects.
Conclusion
Feature engineering is one of the most important steps in building successful machine learning models. Even the most sophisticated algorithms cannot perform well without properly prepared features.
By applying the right Feature Engineering Techniques in Python, data scientists can transform raw datasets into meaningful inputs that help models learn patterns more effectively.
In this guide, we explored ten powerful techniques including handling missing values, encoding categorical variables, feature scaling, feature creation, transformation, outlier handling, feature selection, polynomial features, and dimensionality reduction.
Mastering these techniques will help you build more accurate and reliable machine learning models.
If you are learning machine learning with Python, practicing these Feature Engineering Techniques in Python on real datasets is the best way to improve your skills.
FAQ
What are feature engineering techniques in Python?
Feature engineering techniques in Python are methods used to transform raw data into meaningful features that improve machine learning model performance.
Why is feature engineering important in machine learning?
Feature engineering improves model accuracy, reduces noise in datasets, and helps algorithms detect patterns more effectively.
Which Python libraries are used for feature engineering?
Common libraries include Pandas, NumPy, Scikit-learn, and Featuretools.
What is the difference between feature engineering and feature selection?
Feature engineering involves creating or transforming variables, while feature selection focuses on choosing the most relevant features from an existing dataset.

