
Natural Language Processing (NLP) allows computers to understand and analyze human language. One of the most powerful techniques in NLP is Named Entity Recognition in Python, which enables machines to identify important entities such as people, organizations, locations, and dates within text.
Learning Named Entity Recognition in Python allows developers to build intelligent systems that can automatically extract important information from text.
For example, consider the sentence:
Elon Musk founded SpaceX in California.
A Named Entity Recognition system can automatically detect:
- Elon Musk → PERSON
- SpaceX → ORGANIZATION
- California → LOCATION
This ability is extremely useful for tasks like news analysis, chatbots, search engines, and data extraction systems.
In this beginner-friendly tutorial, you will learn:
- What Named Entity Recognition is
- How NER works in NLP systems
- How to implement Named Entity Recognition in Python using spaCy
- How to visualize entities
- Real-world examples of NER
- Common challenges and best practices
By the end of this guide, you will be able to build your own NER pipeline in Python.
If you are new to NLP projects, you can start with our guide on building an AI text analyzer in Python.
What Is Named Entity Recognition?
Named Entity Recognition (NER) is an NLP technique used to identify and classify real-world entities in text.
These entities can include:
- People
- Organizations
- Locations
- Dates
- Monetary values
- Products
For example:
Sentence:
Google announced a new product in New York on Monday.
NER Output:
| Entity | Type |
|---|---|
| ORG | |
| New York | GPE |
| Monday | DATE |
NER helps computers understand who, what, where, and when in a piece of text.
Because of this capability, Named Entity Recognition in Python is widely used in AI applications that analyze large amounts of text data.
Types of Named Entities in NLP
Named entities represent real-world objects that appear in text. These entities are grouped into different categories depending on what they represent.
Understanding these categories is important when implementing Named Entity Recognition in Python, because NER models assign labels to entities based on these types.
Some of the most common entity types include:
Person (PERSON)
This label identifies names of people.
Example sentence:
Albert Einstein developed the theory of relativity.
NER output:
- Albert Einstein → PERSON
NER systems must recognize both first and last names together as a single entity.
Organization (ORG)
Organizations include companies, institutions, and agencies.
Example:
Microsoft announced a new AI product.
NER output:
- Microsoft → ORG
Organizations can include:
- technology companies
- universities
- government agencies
- non-profit organizations
Geographic Locations (GPE)
This entity type includes locations such as:
- countries
- cities
- states
Example:
The conference was held in Berlin.
NER output:
- Berlin → GPE
Location entities are particularly useful in travel applications, logistics systems, and mapping services.
Dates and Time (DATE)
NER models can detect time-related entities.
Example:
The meeting is scheduled for Monday.
NER output:
- Monday → DATE
Date recognition is useful in:
- calendar applications
- reminder systems
- scheduling software
Monetary Values (MONEY)
This entity type identifies financial values.
Example:
The company raised $5 million in funding.
NER output:
- $5 million → MONEY
Financial analytics platforms often rely on this type of entity extraction.
NER vs Other NLP Techniques
Before diving into implementation, it’s helpful to understand where NER fits in the NLP pipeline.
| NLP Technique | Purpose |
|---|---|
| Tokenization | Splits text into words |
| Stopword Removal | Removes common words like “the” or “is” |
| Lemmatization | Converts words to base form |
| Named Entity Recognition | Detects real-world entities |
Typical NLP workflow:
Raw Text
↓
Tokenization
↓
Stopword Removal
↓
Lemmatization
↓
Named Entity Recognition
In your previous NLP steps, you prepared the text. Now NER extracts meaningful information from it.
Before applying entity recognition, it is important to understand text preprocessing in Python for NLP.
Real-World Applications of Named Entity Recognition
Many modern AI systems rely on Named Entity Recognition in Python to extract valuable information from text.
1. Search Engines
Search engines analyze queries to understand entities.
Example query:
weather in London tomorrow
Entities detected:
- London → Location
- Tomorrow → Date
This helps search engines provide relevant results.
2. News Analysis
NER helps identify important information in news articles.
Example:
Apple announced a partnership with Microsoft in California.
Entities extracted:
- Apple → Organization
- Microsoft → Organization
- California → Location
This allows automated systems to track companies and events in news data.
3. Chatbots and Virtual Assistants
Chatbots use NER to understand user requests.
Example:
Book a flight from Karachi to Dubai tomorrow.
Entities:
- Karachi → Location
- Dubai → Location
- Tomorrow → Date
This allows the chatbot to perform the correct action.
4. Financial Data Extraction
NER is widely used in financial analysis.
Example:
Tesla reported revenue of $24 billion in 2023.
Entities detected:
- Tesla → Organization
- $24 billion → Money
- 2023 → Date
5. Healthcare NLP
Healthcare systems use NER to identify:
- diseases
- medications
- patient data
Example:
The patient was prescribed Paracetamol on Monday.
Entities extracted:
- Paracetamol → Drug
- Monday → Date
How Named Entity Recognition Works
NER systems typically follow a sequence of NLP steps.
Text Input
↓
Tokenization
↓
Part-of-Speech Tagging
↓
NER Model
↓
Entities Extracted
There are three main approaches used in NER systems.
Rule-Based Systems
Early NER systems used handwritten linguistic rules.
Example:
Words starting with capital letters might be names.
However, rule-based systems struggle with complex language.
Machine Learning Models
Machine learning improved NER accuracy by training models on labeled data.
The model learns patterns from thousands of sentences.
Deep Learning Models
Modern NER systems use deep learning.
Many state-of-the-art models use transformer architectures such as BERT, which significantly improve entity recognition accuracy by understanding context in sentences.
Libraries like spaCy include pre-trained models that use these advanced techniques.
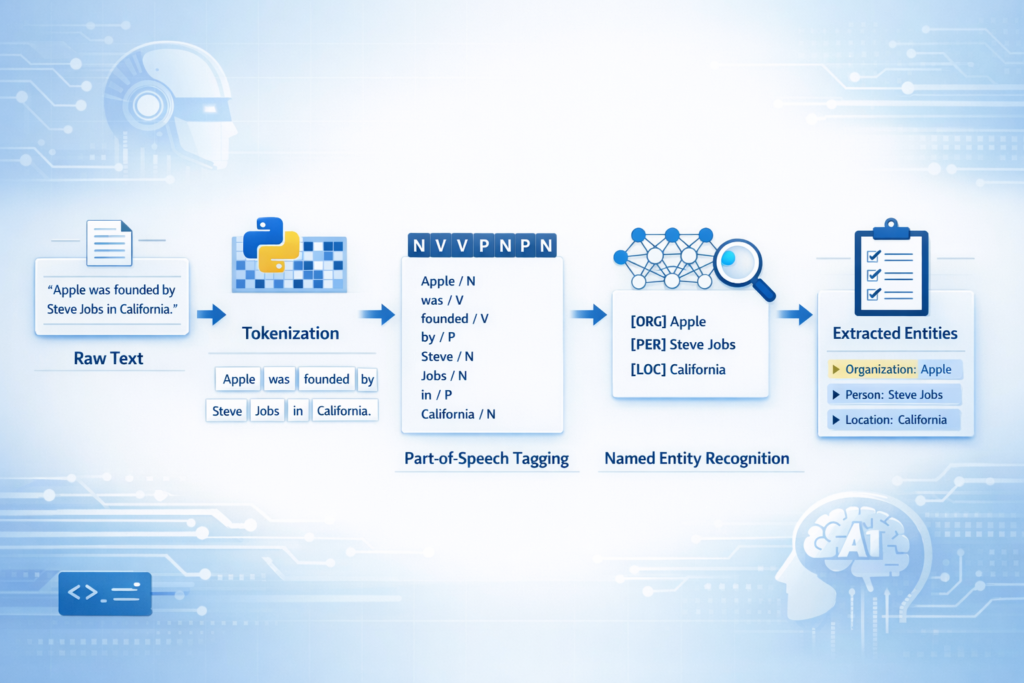
Named Entity Recognition Pipeline in NLP
NER does not work as a standalone process. Instead, it is part of a larger Natural Language Processing pipeline.
The typical pipeline includes several stages.
1. Text Input
The process begins with raw text data.
Example:
Barack Obama visited Germany in 2016.
2. Tokenization
Tokenization splits text into smaller units called tokens.
Example tokens:
- Barack
- Obama
- visited
- Germany
- 2016
The first step in most NLP pipelines is tokenization, which splits text into smaller units called tokens.
3. Part-of-Speech Tagging
Each token is labeled with its grammatical role.
Example:
| Word | POS Tag |
|---|---|
| Barack | Proper noun |
| visited | Verb |
| Germany | Proper noun |
These grammatical hints help the model identify entities.
4. Entity Detection
The NER model analyzes tokens and determines whether they belong to an entity.
Example result:
- Barack Obama → PERSON
- Germany → GPE
- 2016 → DATE
This pipeline helps transform unstructured text into structured information.
Installing spaCy for Named Entity Recognition
To implement Named Entity Recognition in Python, we will use the popular NLP library spaCy.
Install spaCy
Open your terminal and run:
pip install spacy
Download the English Model
python -m spacy download en_core_web_sm
This model includes:
- tokenizer
- part-of-speech tagger
- dependency parser
- Named Entity Recognition model
Now we are ready to use spaCy for NER.
Libraries like spaCy make Named Entity Recognition in Python accessible even for beginners.
You can explore the official spaCy documentation for more details about NLP models.
Why spaCy Is Popular for Named Entity Recognition
There are several NLP libraries available for Python, but spaCy is one of the most widely used tools for Named Entity Recognition in Python.
Here are some reasons why spaCy is popular among developers.
Fast Processing Speed
spaCy is optimized for performance and can process large volumes of text efficiently.
This makes it suitable for:
- real-time applications
- production systems
- large-scale data pipelines
Pretrained NLP Models
spaCy provides pretrained models that already include:
- tokenization
- part-of-speech tagging
- dependency parsing
- named entity recognition
This allows beginners to start using NLP immediately without training their own models.
Easy-to-Use API
spaCy has a simple and intuitive API.
For example:
doc = nlp(text)
With just one line of code, spaCy processes the entire NLP pipeline.
Visualization Tools
spaCy also includes tools like displacy, which allow developers to visualize NLP outputs easily.
This is particularly useful for learning and debugging.
spaCy Model Sizes Explained
spaCy provides several models with different sizes and capabilities.
| Model | Accuracy | Speed |
|---|---|---|
| en_core_web_sm | Lower | Fast |
| en_core_web_md | Medium | Moderate |
| en_core_web_lg | High | Slower |
| en_core_web_trf | Very High | Slow |
When to Use Each Model
Small model (sm)
Best for beginners and tutorials.
Medium / Large models
Better accuracy for production applications.
Transformer model (trf)
Highest accuracy but requires more computing power.
For most beginners learning Named Entity Recognition in Python, the small model is sufficient.
Basic Named Entity Recognition Example in Python
Now let’s implement our first NER example in Python.
import spacynlp = spacy.load("en_core_web_sm")text = "Apple was founded by Steve Jobs in California."doc = nlp(text)for ent in doc.ents:
print(ent.text, ent.label_)Output:
Apple ORG
Steve Jobs PERSON
California GPE
Understanding the Code
Load spaCy
nlp = spacy.load("en_core_web_sm")This loads the pre-trained English NLP model.
Process the Text
doc = nlp(text)
The model analyzes the sentence.
Extract Entities
for ent in doc.ents:
spaCy automatically stores detected entities in doc.ents.
Print Entities
print(ent.text, ent.label_)
This prints both the entity text and its type.

Understanding Entity Labels in spaCy
spaCy uses labels to classify entities.
Common labels include:
| Label | Meaning |
|---|---|
| PERSON | People |
| ORG | Organizations |
| GPE | Countries or cities |
| DATE | Dates |
| MONEY | Monetary values |
| PRODUCT | Products |
Example sentence:
Microsoft launched Windows 11 in 2021.
NER Output:
| Entity | Label |
|---|---|
| Microsoft | ORG |
| Windows 11 | PRODUCT |
| 2021 | DATE |
These labels help machines structure unorganized text data.
spaCy provides detailed documentation on named entity recognition and entity labels.
Visualizing Named Entities with spaCy
spaCy provides a visualization tool called displacy.
This highlights entities directly in text.
Example:
from spacy import displacydisplacy.render(doc, style="ent")
This will display the sentence with colored entity highlights.

Important Note for Beginners
Behavior depends on environment.
In Jupyter Notebook
displacy.render(doc, style="ent")
works directly.
In Python Scripts
You should use:
displacy.serve(doc, style="ent")
This launches a local web server to display the visualization in your browser.
Many beginners get confused here, so remember this difference.
Practical Example: Extract Entities from News Text
Let’s apply Named Entity Recognition in Python to extract entities from a real-world news sentence.
Let’s use Named Entity Recognition in Python on a real-world example.
Tesla CEO Elon Musk announced a new factory in Texas in 2023.
Python code:
import spacynlp = spacy.load("en_core_web_sm")text = """
Tesla CEO Elon Musk announced a new factory in Texas in 2023.
"""doc = nlp(text)for ent in doc.ents:
print(ent.text, ent.label_)Expected output:
Tesla ORG
Elon Musk PERSON
Texas GPE
2023 DATE
This type of entity extraction can be used for:
- news monitoring
- market analysis
- research tools
- automated data pipelines
Reading Text from a File
You can also analyze text files.
Example:
with open("article.txt", "r") as file:
text = file.read()doc = nlp(text)for ent in doc.ents:
print(ent.text, ent.label_)This allows you to process large documents automatically.
Common Challenges in Named Entity Recognition
Although powerful, NER systems are not perfect.
Ambiguity
Example:
Apple
This could refer to:
- Apple company
- Apple fruit
The model must rely on context.
Context Dependency
Example:
Jordan
Could mean:
- the country
- a person
NER models use surrounding words to determine the meaning.
Informal Text
Social media text is harder to analyze.
Example:
gonna meet elon tomorrow lol
Misspellings and slang can confuse models.
Limitations of Named Entity Recognition
Although NER is powerful, it still has several limitations.
Understanding these limitations helps developers design better NLP systems.
Limited Context Understanding
NER models rely heavily on context. If the context is unclear, the model may produce incorrect predictions.
Example:
Amazon released a new product.
Amazon could refer to:
- the technology company
- the Amazon rainforest
Without additional context, the model may struggle.
Domain-Specific Language
Many industries use specialized terminology.
For example, in medicine:
The patient was treated with Ibuprofen.
General NER models might not recognize medical entities accurately.
Custom models trained on medical data perform better.
Multilingual Challenges
NER performance varies across languages.
Models trained on English may not perform well on other languages unless separate models are used.
Improving NER Accuracy
There are several ways to improve Named Entity Recognition in Python.
Use Larger Models
en_core_web_md
en_core_web_lg
These models provide better accuracy.
Train Custom NER Models
If you work in specialized fields like finance or medicine, you may need to train a custom NER model.
Preprocess Text
Cleaning text improves model performance.
Steps include:
- tokenization
- removing noise
- normalizing text
Use Domain-Specific Data
Models trained on domain-specific datasets perform better.
Example:
- legal NER models
- medical NER models
Techniques like stemming and lemmatization can also help improve text processing before entity recognition.
Removing unnecessary words using stopword removal in NLP can improve model performance.
Custom Named Entity Recognition Models in spaCy
Sometimes the default spaCy model may not detect entities specific to your domain. In such cases, developers can train custom models for Named Entity Recognition in Python.
Custom NER models are especially useful in industries such as:
- finance
- healthcare
- legal analytics
- e-commerce
For example, a financial application may need to detect entities like:
- stock symbols
- company tickers
- financial instruments
The default spaCy model may not recognize these specialized entities.
spaCy allows developers to train a custom NER model using labeled datasets. The training process involves providing examples where entities are manually annotated.
Example training data:
TRAIN_DATA = [
("Tesla released a new car", {"entities": [(0, 5, "ORG")]}),
("Elon Musk is the CEO of Tesla", {"entities": [(0, 9, "PERSON"), (24, 29, "ORG")]})
]
During training, the model learns patterns from these labeled examples.
The typical workflow for building a custom Named Entity Recognition in Python model includes:
- Collecting training data
- Annotating entities
- Training the spaCy model
- Evaluating model performance
Custom models significantly improve accuracy when working with domain-specific text.
Best Practices When Using Named Entity Recognition
Follow these best practices when implementing NER.
- Always preprocess text
- Choose the correct spaCy model
- Validate entity results
- Test on real-world datasets
- Use custom training for specialized applications
These practices ensure more accurate entity extraction.
Performance Considerations When Using NER
When building large NLP applications, performance becomes an important factor. Efficient implementation of Named Entity Recognition in Python ensures that systems can process large volumes of text quickly.
Several factors influence NER performance.
Model Size
Larger spaCy models provide higher accuracy but require more computational resources.
For example:
| Model | Performance |
|---|---|
| en_core_web_sm | Fast but less accurate |
| en_core_web_md | Balanced performance |
| en_core_web_lg | Higher accuracy |
| en_core_web_trf | Transformer-based, most accurate |
For production systems handling large datasets, choosing the right model is important.
Batch Processing
Instead of processing text one sentence at a time, spaCy allows batch processing using the nlp.pipe() method.
Example:
texts = [
"Google opened a new office in London.",
"Microsoft acquired GitHub in 2018."
]for doc in nlp.pipe(texts):
for ent in doc.ents:
print(ent.text, ent.label_)
Batch processing significantly improves the speed of Named Entity Recognition in Python pipelines.
Hardware Acceleration
Transformer-based models may benefit from GPU acceleration.
When working with large datasets, GPU processing can greatly speed up entity recognition tasks.
When Should You Use Named Entity Recognition?
Named Entity Recognition is particularly useful when working with large amounts of text data.
Here are situations where NER is extremely valuable.
Information Extraction
NER can extract structured information from unstructured text.
Example:
Extract:
- company names
- locations
- dates
from news articles.
Document Analysis
Businesses often analyze thousands of documents.
NER helps automatically identify important information.
Examples include:
- legal documents
- contracts
- research papers
Social Media Monitoring
NER helps track mentions of:
- brands
- celebrities
- products
This is widely used in marketing analytics.
Data Automation
NER can automatically populate databases by extracting structured information from text sources.
This reduces manual data entry and improves efficiency.
Conclusion
Named Entity Recognition is one of the most powerful techniques in Natural Language Processing. It enables computers to identify real-world entities such as people, organizations, locations, and dates within text.
In this tutorial, you learned:
- what Named Entity Recognition in Python is
- how NER works in NLP systems
- how to use spaCy for entity extraction
- how to visualize entities
- real-world applications of NER
With just a few lines of code, Python developers can build systems that automatically extract meaningful information from large volumes of text.
As you continue exploring NLP, mastering Named Entity Recognition in Python will help you build powerful text analysis and information extraction systems.
As you continue learning NLP, you can explore:
- training custom NER models
- building information extraction systems
- integrating NER into AI applications
Experiment with your own datasets and see how Named Entity Recognition in Python can transform raw text into structured knowledge.
FAQ
What is Named Entity Recognition in NLP?
Named Entity Recognition is an NLP technique that identifies entities such as people, organizations, locations, and dates within text.
Which Python library is best for NER?
spaCy is one of the most popular and beginner-friendly libraries for implementing Named Entity Recognition in Python.
Can I train a custom NER model in spaCy?
Yes. spaCy allows developers to train custom NER models for domain-specific entity recognition tasks.
Is spaCy free to use?
Yes. spaCy is an open-source NLP library and can be used for both personal and commercial projects.
What is the difference between NER and keyword extraction?
Named Entity Recognition identifies specific entities such as people and locations, while keyword extraction identifies important words or topics within a document.
Is Named Entity Recognition part of machine learning?
Yes. Modern Named Entity Recognition systems are typically built using machine learning or deep learning models trained on annotated text datasets.
Can Named Entity Recognition work in real-time systems?
Yes. Libraries like spaCy are optimized for fast processing, making them suitable for real-time applications such as chatbots and search engines.

