
1. Introduction
Sentiment Analysis in Python is one of the most powerful techniques in Natural Language Processing (NLP) used to automatically identify emotions, opinions, and attitudes in text data.
Imagine waking up one morning to discover that a single negative tweet about your brand had gone viral overnight, sending your company’s stock price plummeting by 5%.
Sentiment analysis, also known as opinion mining, is a computational approach to identifying and extracting subjective information from text. It represents one of the most practical and impactful applications of Natural Language Processing (NLP), enabling organizations to automatically determine whether a piece of writing expresses positive, negative, or neutral emotions. Since its early days in the 2000s—when crude keyword matching was the primary technique—sentiment analysis has evolved into a sophisticated discipline powered by deep learning models capable of understanding context, detecting sarcasm, and recognizing nuanced emotional expressions.
Python has emerged as the undisputed champion for sentiment analysis and NLP tasks. Its rich ecosystem of libraries—including NLTK, TextBlob, spaCy, and Hugging Face Transformers—makes it accessible for beginners while remaining powerful enough for enterprise-grade production systems. Python’s readable syntax, vibrant community, and extensive learning resources create the ideal environment for anyone stepping into the world of machine learning and text analytics.
In this guide, you will progress through a carefully structured learning journey: from understanding core NLP concepts to building your first rule-based sentiment analyzer, then advancing through machine learning approaches, and finally exploring cutting-edge transformer-based models like BERT that have redefined accuracy benchmarks since 2018. By the end, you will have both the knowledge and practical tools to implement sentiment analysis in real-world applications.
2. Understanding Sentiment Analysis
2.1 What is Sentiment Analysis?
Sentiment analysis is the automated process of identifying and categorizing opinions expressed in text, particularly to determine the writer’s attitude toward a topic, product, or service. At its most fundamental level, it classifies text into three primary buckets: positive, negative, or neutral. However, modern approaches extend far beyond this simple trichotomy—detecting a rich spectrum of emotions including joy, anger, sadness, fear, and surprise, giving organizations nuanced insights into customer psychology and market dynamics.
The science underpinning sentiment analysis combines computational linguistics, machine learning, and data mining. The foundational premise is that language patterns carry emotional weight—certain words and phrases consistently appear in positive contexts (“excellent,” “amazing,” “love”), while others reliably signal negativity (“terrible,” “disappointed,” “hate”). Yet effective sentiment analysis demands much more than simple word counting. It must grapple with negation (“not bad” is actually positive), intensity modifiers (“very good” vs. “somewhat good”), contrastive conjunctions (“the food was great, but the service was appalling”), and the many ways humans convey opinions through implication and cultural context.

2.2 Types of Sentiment Analysis
Document-Level Analysis: Classifies the overall sentiment of an entire document, review, or article as a single unit. This approach is ideal for quickly summarizing large volumes of customer feedback or news articles at scale.
Sentence-Level Analysis: Examines each sentence independently, allowing more granular detection within longer documents—especially valuable for reviews that discuss multiple product features with varying sentiments.
Aspect-Based Sentiment Analysis (ABSA): The most sophisticated approach, identifying sentiment toward specific features or aspects within a single piece of text. A restaurant review, for example, might express positive sentiment about the food while expressing frustration about slow service.
Emotion Detection: Goes beyond the positive/negative binary to identify specific emotions—joy, anger, sadness, fear, disgust, and surprise—providing deeper psychological insights into customer responses.
2.3 Real-World Applications
The business applications of sentiment analysis are both broad and deeply impactful. Companies monitor brand reputation across social platforms, track customer satisfaction trends, and identify emerging issues before they escalate. Marketing teams measure campaign reception in real time, while product development teams use sentiment data to prioritize feature roadmaps. Financial institutions analyze news headlines, earnings call transcripts, and social media streams to inform trading decisions. Customer service operations integrate sentiment detection to triage support tickets, ensuring the most frustrated customers receive immediate attention. The technology has even found its way into political analysis, healthcare feedback monitoring, and academic research—demonstrating the extraordinary versatility of sentiment analysis as a discipline.
3. Setting Up Your Python Environment
3.1 Essential Libraries Overview
NLTK (Natural Language Toolkit): The foundational library for NLP in Python, offering tokenizers, corpora, lexical resources, and access to WordNet and stopword lists. NLTK forms the backbone of most text preprocessing pipelines.
TextBlob: A beginner-friendly library built on NLTK and Pattern that provides a simple, intuitive API for common NLP tasks. Its straightforward sentiment scoring makes it ideal for learning core concepts.
spaCy: An industrial-strength library designed for production use. SpaCy offers blazing-fast text processing with pre-trained models for multiple languages, making it suitable for large-scale pipelines.
Transformers (Hugging Face): The state-of-the-art library for accessing pre-trained models like BERT, RoBERTa, and GPT variants. These models represent the absolute cutting edge of sentiment analysis accuracy.
Pandas & NumPy: Essential for data manipulation and numerical operations, handling everything from loading datasets to storing and aggregating analysis results.
Another important preprocessing step is stopword removal in Python for NLP to eliminate common words that add little meaning.
3.2 Installation and Setup
Follow these steps to configure a clean Python environment for sentiment analysis:
Step 1: Create and activate a virtual environment
python -m venv sentiment_env
source sentiment_env/bin/activate # Linux/Mac
sentiment_env\Scripts\activate # WindowsStep 2: Install core libraries
pip install nltk textblob spacy transformers
pip install pandas numpy scikit-learn torchStep 3: Download required NLTK data
import nltk
nltk.download('vader_lexicon')
nltk.download('stopwords')
nltk.download('punkt')Step 4: Download spaCy English model
python -m spacy download en_core_web_sm4. Core NLP Concepts for Sentiment Analysis
4.1 Text Preprocessing Fundamentals
Tokenization: The process of breaking text into individual units called tokens—typically words or sentences. Proper tokenization handles punctuation, contractions, and special characters. Modern transformer models use subword tokenization (e.g., Byte Pair Encoding), which splits rare words into meaningful subunits for better generalization.
Stopword Removal: The elimination of high-frequency words like “the,” “is,” and “at” that contribute little semantic value. However, blind stopword removal can backfire—phrases like “not good” lose their negation if “not” is stripped, inadvertently flipping the sentiment.
Stemming and Lemmatization: Techniques that reduce words to their base forms. Stemming applies crude heuristics (“running” becomes “run”), while lemmatization uses vocabulary knowledge for more accurate results (“better” correctly maps to “good”).
Before performing sentiment analysis, proper text preprocessing in Python for NLP is essential for cleaning and preparing textual data.
4.2 Feature Extraction Techniques
Bag of Words (BoW): The simplest text representation—a frequency vector over a fixed vocabulary. Fast and interpretable, but it discards word order and semantic relationships.
TF-IDF (Term Frequency-Inverse Document Frequency): An improvement on BoW that weights terms by their uniqueness across documents. TF-IDF elevates distinctive sentiment-bearing words while downweighting common filler terms.
Word Embeddings (Word2Vec, GloVe): Dense vector representations that capture semantic relationships. Words with similar meanings cluster together in the embedding space, enabling richer sentiment modeling.
Contextual Embeddings (BERT): Dynamic embeddings where the same word receives different vector representations depending on surrounding context. This capability dramatically improves accuracy for ambiguous or context-sensitive expressions like sarcasm.
The first step in most NLP pipelines is Python tokenization for NLP, which splits raw text into words or sentences.
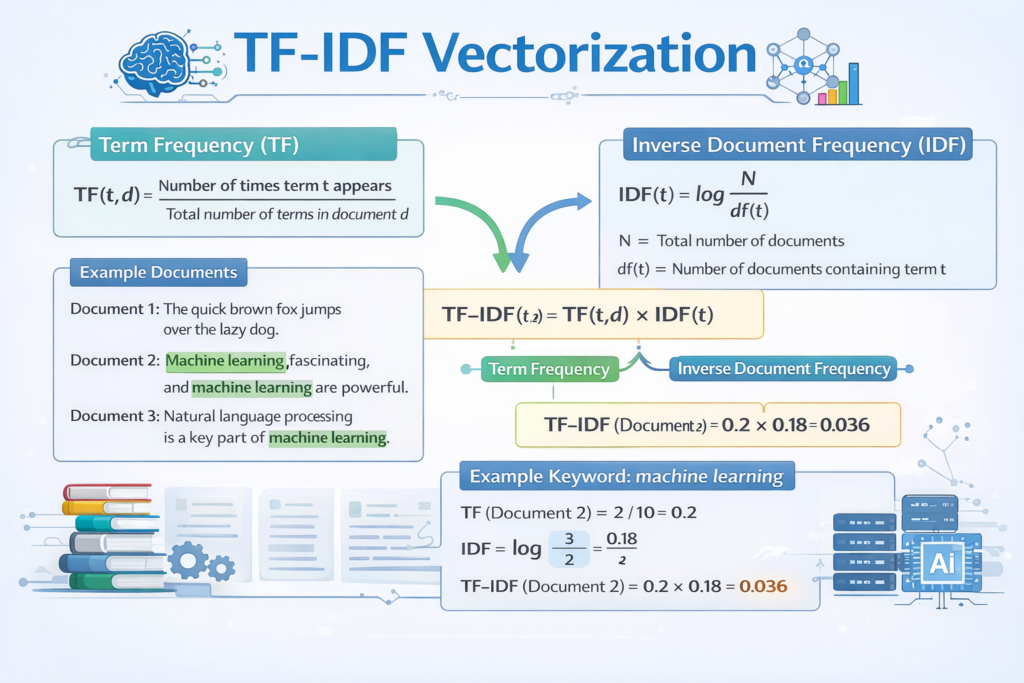
4.3 Understanding Sentiment Lexicons
VADER (Valence Aware Dictionary and sEntiment Reasoner): A lexicon specifically designed for social media analysis. VADER natively handles emojis, slang, capitalization intensity (“GREAT” vs. “great”), and punctuation emphasis (“awesome!!!”), making it particularly effective for informal text.
AFINN and SentiWordNet: Alternative lexicon-based approaches. AFINN assigns numerical sentiment scores (-5 to +5) to 3,300+ words, while SentiWordNet extends WordNet with positivity, negativity, and objectivity scores for synsets, enabling fine-grained analysis.
Techniques such as stemming vs lemmatization in Python for NLP help reduce words to their base form for better analysis.
5. Building Your First Sentiment Analysis Model
5.1 Rule-Based Approach with VADER
VADER is the perfect starting point for sentiment analysis beginners. It requires no training data and delivers surprisingly strong performance on social media and review text straight out of the box.
from nltk.sentiment import SentimentIntensityAnalyzer
import nltk
nltk.download('vader_lexicon')sia = SentimentIntensityAnalyzer()# Analyze sample texts
texts = [
'This movie was absolutely AMAZING!!! Best film I have seen all year.',
'The service was terrible and the food arrived cold.',
'The food was great, but the service was horrible.',
'Not bad for the price. Could be better though.'
]for text in texts:
scores = sia.polarity_scores(text)
sentiment = 'Positive' if scores['compound'] >= 0.05
else 'Negative' if scores['compound'] <= -0.05
else 'Neutral'
print(f'Text: {text[:50]}...')
print(f'Scores: {scores} -> {sentiment}\n')VADER returns four metrics: pos, neg, neu (proportions of text with each sentiment), and compound (normalized aggregate score from -1 to +1). A compound score ≥ 0.05 signals positive sentiment, ≤ -0.05 signals negative, and anything in between is neutral. Notice how VADER correctly handles the contrastive conjunction in the third example, flagging mixed sentiment.
5.2 Machine Learning Approach with Scikit-Learn
For higher accuracy on structured datasets, traditional machine learning classifiers paired with TF-IDF features offer a significant upgrade over rule-based systems.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split# Assuming X = list of review texts, y = list of labels (0=neg, 1=pos)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
pipeline = Pipeline([
('tfidf', TfidfVectorizer(max_features=10000, ngram_range=(1, 2))),
('clf', LogisticRegression(max_iter=1000))
])pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)
print(classification_report(y_test, y_pred))This pipeline vectorizes raw text with TF-IDF (including bigrams for better context capture), trains a Logistic Regression classifier, and evaluates using precision, recall, F1-score, and accuracy. Logistic Regression typically outperforms Naive Bayes on larger datasets while remaining highly interpretable. Support Vector Machines (SVM) are also an excellent choice, often achieving 82–85% accuracy on benchmark datasets like IMDb reviews.
5.3 Deep Learning with Neural Networks
Long Short-Term Memory (LSTM) networks capture sequential dependencies in text that bag-of-words approaches miss entirely, making them particularly effective for longer documents.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense, Dropoutmodel = Sequential([
Embedding(input_dim=10000, output_dim=128, input_length=200),
LSTM(64, dropout=0.2, recurrent_dropout=0.2),
Dense(32, activation='relu'),
Dropout(0.3),
Dense(1, activation='sigmoid')
])model.compile(optimizer='adam', loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(X_train_seq, y_train, epochs=5, batch_size=64,
validation_split=0.1)The embedding layer learns dense word representations during training; the LSTM layer captures temporal dependencies; dropout layers prevent overfitting. LSTM models typically achieve 85–90% accuracy on sentiment benchmarks, especially for longer review texts where word order and context accumulate meaningful signal.
6. Advanced Techniques and Tools
6.1 Transformer-Based Models with Hugging Face
The 2017 introduction of the Transformer architecture fundamentally changed NLP. Unlike RNNs, transformers process all tokens simultaneously through self-attention mechanisms, capturing long-range dependencies with exceptional efficiency. BERT (Bidirectional Encoder Representations from Transformers), released by Google in 2018, leveraged this architecture with bidirectional pretraining on massive corpora, enabling fine-tuning on downstream tasks with minimal labeled data.
The Hugging Face Transformers library makes state-of-the-art models accessible in just a few lines:
from transformers import pipeline# Quick inference with pre-trained model
sentiment_pipeline = pipeline(
'sentiment-analysis',
model='distilbert-base-uncased-finetuned-sst-2-english'
)texts = [
'The transformer architecture has completely revolutionized NLP.',
'I waited three hours and never received my order. Unacceptable.'
]results = sentiment_pipeline(texts)
for text, result in zip(texts, results):
print(f'Text: {text[:50]}')
print(f'Sentiment: {result["label"]} (confidence: {result["score"]:.3f})\n')Modern sentiment analysis models can be easily implemented using the Hugging Face Transformers library.
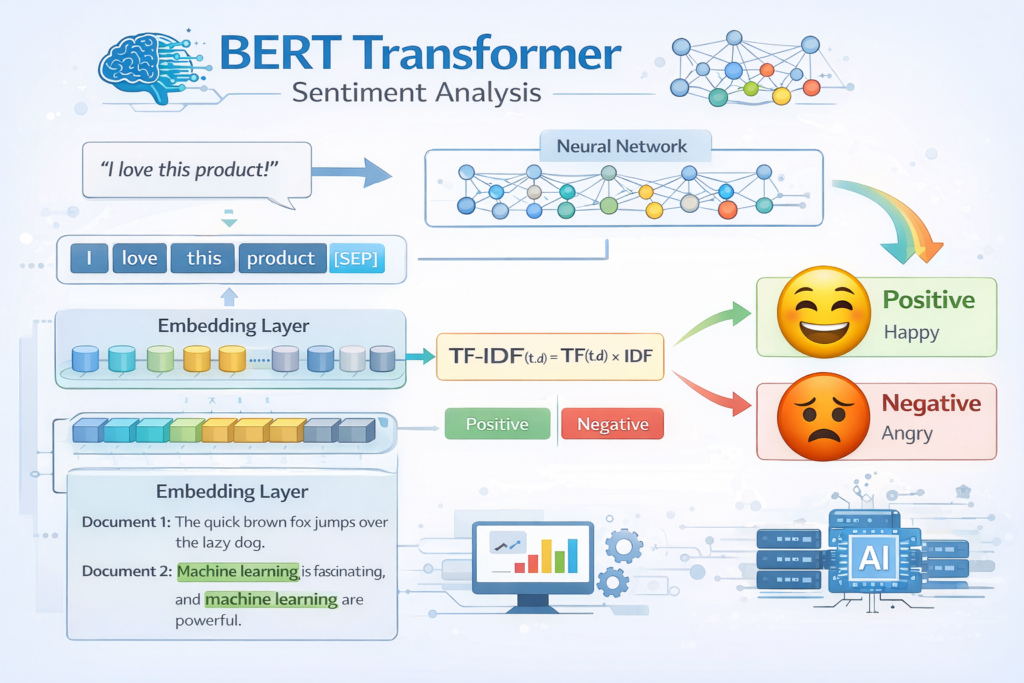
6.2 Handling Challenges in Sentiment Analysis
Sarcasm and Irony Detection: “Oh great, another Monday” is technically positive word usage expressing negative sentiment. Contextual embeddings from transformers significantly improve sarcasm detection, though it remains an open research challenge. Specialized datasets like SarcasmCorpus can be used for fine-tuning.
Multilingual Sentiment Analysis: Models like XLM-RoBERTa provide cross-lingual capabilities, enabling sentiment analysis across 100+ languages without language-specific fine-tuning. Translation-based pipelines offer an alternative when target-language data is scarce.
Domain Adaptation: Sentiment expression is domain-specific—”sick” is slang for “excellent” in skateboarding culture but signals illness in healthcare contexts. Fine-tuning pre-trained models on domain-specific labeled data is the most effective mitigation strategy.
Aspect Extraction: Identifying which specific product features or service attributes receive positive or negative sentiment requires named entity recognition combined with dependency parsing—an area where spaCy and fine-tuned BERT models excel.
6.3 Comparison of Sentiment Analysis Approaches
| Approach | Accuracy | Speed | Best Use Case |
| Rule-Based (VADER) | 70–75% | Very Fast | Social Media / Informal Text |
| Traditional ML (SVM / LR) | 80–85% | Fast | Product Reviews / Structured Text |
| LSTM / Deep Learning | 85–90% | Moderate | Long Documents / Sequential Text |
| Transformers (BERT) | 92–95% | Slower | Complex / High-Stakes Text Analysis |
Table 1: Comparison of Sentiment Analysis Approaches
7. Real-World Applications and Case Studies
7.1 Social Media Monitoring
Brands deploy sentiment analysis pipelines that continuously scan Twitter, Reddit, Instagram, and news feeds for brand mentions, competitor discussions, and emerging trends. Dashboards aggregate sentiment trends over time, enabling PR teams to detect crises within minutes rather than hours. When a product flaw surfaces in social conversations, real-time sentiment shifts trigger automated alerts, enabling brands to respond proactively before reputational damage compounds.
7.2 Customer Service Enhancement
Customer service platforms integrate sentiment scores into ticketing systems, automatically elevating high-frustration cases to senior agents. Chatbots equipped with sentiment detection modulate their tone in real time—offering empathy when detecting anger and shifting to efficiency mode for neutral informational queries. Companies report 20–30% reductions in customer churn when sentiment-driven prioritization is implemented, as the most dissatisfied customers receive faster, more personalized attention.
7.3 Market Research and Competitive Intelligence
Product teams track sentiment trajectories for their own launches versus competitors’ releases, gaining unbiased consumer signal that traditional surveys cannot capture at scale. E-commerce platforms analyze hundreds of thousands of product reviews to surface the specific attributes driving satisfaction or dissatisfaction, directly informing product roadmap decisions. Longitudinal sentiment tracking over months and years reveals consumer preference shifts before they manifest in sales data.
7.4 Financial Market Analysis
Quantitative hedge funds and algorithmic trading firms have integrated sentiment analysis into their alpha generation strategies for over a decade. By analyzing earnings call transcripts, financial news, SEC filings, and social media discourse around publicly traded companies, they construct sentiment signals that predict short-term price movements. Research consistently shows that news sentiment has statistically significant predictive power for equity returns over 1–5 day horizons, making sentiment analysis a core component of modern quantitative finance.
8. Best Practices and Common Pitfalls
8.1 Data Quality Considerations
- Ensure training data is representative of the target domain, demographic, and time period—models trained on 2015 Twitter data may underperform on 2026 social media with different slang and cultural references.
- Address class imbalance proactively. Sentiment datasets are typically skewed toward positive reviews; use stratified sampling, oversampling (SMOTE), or class-weighted loss functions to prevent classifier bias.
- Implement rigorous data cleaning: strip HTML tags, normalize Unicode, handle emojis consistently (either convert to text or remove), and standardize abbreviations.
- Consider data augmentation for small domain-specific datasets using back-translation (translate to another language and back) or synonym replacement.
8.2 Common Mistakes to Avoid
- Neglecting context: Words shift meaning dramatically across domains and conversational contexts. Always evaluate models on domain-representative test sets, not just benchmark datasets.
- Over-relying on accuracy alone: For imbalanced datasets (90% positive reviews), a classifier that predicts “positive” for everything achieves 90% accuracy while being completely useless. Always report precision, recall, and F1-score.
- Ignoring language evolution: Slang, cultural references, and sentiment expressions change over time. Schedule periodic model retraining and monitor performance drift in production.
- Neglecting edge cases: Systematically test models against sarcasm, negation, double negatives, conditional statements, and mixed-sentiment texts before production deployment.
8.3 Performance Optimization Tips
- Batch API requests: Transformer models process batches far more efficiently than individual texts. Group inputs into batches of 32–64 for 4–10x throughput improvement.
- Cache preprocessing results: Text cleaning and tokenization are computationally repetitive. Cache preprocessed features to disk when reanalyzing the same corpus multiple times.
- Leverage GPU acceleration: Deep learning inference is 10–100x faster on GPU. Use torch.cuda for PyTorch models and ensure your environment has CUDA-enabled hardware for production workloads.
- Use distilled models for latency-sensitive applications: DistilBERT offers 97% of BERT’s accuracy at 60% of the size and twice the speed—ideal for real-time applications.
9. Future Trends in Sentiment Analysis (2026 and Beyond)
Multimodal Sentiment Analysis: The next frontier combines text with audio prosody, facial expressions, and visual cues for comprehensive emotion detection. This is particularly transformative for video content analysis—understanding not just what creators say, but how they say it.
Low-Resource Language Support: Cross-lingual transfer learning is rapidly democratizing sentiment analysis for the world’s 7,000+ languages. Models like mBERT and XLM-RoBERTa enable zero-shot sentiment analysis in languages with minimal training data.
Explainable AI (XAI) for Sentiment: As sentiment analysis informs high-stakes decisions in finance, healthcare, and legal domains, the demand for interpretable models grows. Techniques like LIME, SHAP, and attention visualization are becoming standard requirements for production deployments.
Real-Time Analysis at Scale: Model distillation, quantization, and hardware acceleration advances are enabling sentiment analysis of billions of data points in near real-time—making comprehensive social listening economically viable for organizations of any size.
Emotion AI Integration: Sentiment analysis is converging with broader affective computing—systems that understand the full spectrum of human emotional states across modalities—opening transformative applications in mental health support, adaptive learning systems, and personalized customer experiences.
10. Conclusion
Sentiment analysis in Python represents one of the most accessible entry points into the broader world of natural language processing and machine learning—yet it offers unlimited depth for those who choose to explore further. The journey from a simple VADER implementation to fine-tuning a BERT model for domain-specific analysis is a microcosm of the broader NLP landscape: conceptually approachable but technically rich.
The recommended path forward is sequential and deliberate. Start with VADER for rapid prototyping and social media analysis. Graduate to TF-IDF with Logistic Regression or SVM for structured review datasets requiring higher accuracy. Explore LSTM networks when sequential context matters. And invest in transformer-based models when accuracy is paramount and computational resources permit.
Above all, remember that the best model is not necessarily the most sophisticated one—it is the one that best serves your specific use case, data characteristics, and production constraints. Continuous validation against real-world data, domain adaptation, and monitoring for model drift are as important as the initial model selection.
Now it is your turn. Clone the companion repository, load one of the recommended datasets, and build your first sentiment analyzer. The NLP community is vibrant, the tooling has never been more accessible, and the applications are genuinely transformative. Start today.
Additional Resources
Recommended Datasets
- IMDb Movie Reviews Dataset: 50,000 labeled movie reviews for binary sentiment classification—the standard benchmark for sentiment analysis research.
- Twitter Sentiment Analysis Dataset: Millions of tweets with sentiment labels, ideal for social media analysis and VADER benchmarking.
- Amazon Product Reviews: Large-scale multi-domain review data with star ratings, perfect for aspect-based sentiment analysis.
- Yelp Dataset: Business reviews with ratings, useful for domain-specific restaurant and service sentiment analysis.
Further Reading
- “Natural Language Processing with Python” by Steven Bird, Ewan Klein, and Edward Loper — the definitive NLTK reference.
- “Deep Learning for Natural Language Processing” by Palash Goyal, Sumit Pandey, and Karan Jain.
- Hugging Face Documentation and Model Hub: huggingface.co — thousands of pre-trained sentiment models ready to deploy.
- Stanford NLP Group resources and CS224N course materials — world-class free education in deep learning for NLP.
SEO & Meta Information
| Element | Content |
| Title | Sentiment Analysis in Python: A Beginner’s Guide to Analyzing Text Emotions with NLP (2026) |
| Focus Keyword | Sentiment Analysis in Python |
| Meta Description | Learn sentiment analysis in Python from scratch. This beginner-friendly guide covers NLP basics, VADER, machine learning, and transformer models for analyzing text emotions. |
| Target Word Count | ~3,000 words |
| Target Audience | Beginners to intermediate Python developers interested in NLP and machine learning |
| Secondary Keywords | NLP Python, text analysis, VADER sentiment, BERT sentiment analysis, opinion mining |
Table 2: Blog SEO Meta Information

