
1. Introduction: From Text to Math
Computers are powerful at processing numbers, but they cannot directly understand human language. When we read a sentence, we automatically recognize the meaning of words, their relationships, and the context in which they appear. Machines, however, only understand numbers.
This is where Word Embeddings in Python become essential in Natural Language Processing (NLP).
Before modern NLP techniques were developed, computers treated words simply as symbols. For example, in traditional text processing, the word “cat” was completely unrelated to the word “kitten.” Even though humans know they are closely related, machines saw them as totally different.
Word embeddings solve this problem by converting words into numerical vectors that capture semantic meaning.
This means a machine can understand relationships such as:
- Cat is similar to kitten
- King is related to queen
- Paris is related to France
Instead of treating words as isolated tokens, word embeddings represent them in a mathematical vector space where similar words appear closer together.
In this tutorial, you will learn:
- What word embeddings are
- Why they are important in NLP
- How Word2Vec works
- How GloVe works
- How to implement Word Embeddings in Python using practical code examples
By the end of this guide, you will understand one of the most fundamental building blocks of modern AI systems.
In this guide, we will learn how to implement Word Embeddings in Python using practical examples with Word2Vec and GloVe.
Text normalization techniques such as stemming vs lemmatization in NLP help reduce words to their base forms.
2. Why Traditional Text Representation Was Not Enough
Before word embeddings were introduced, NLP models relied on methods like:
- Bag of Words (BoW)
- One-Hot Encoding
- TF-IDF
These methods helped machines process text but had serious limitations.
Before creating word embeddings, text usually goes through several steps such as text preprocessing in Python, tokenization, and stopword removal.
Many NLP pipelines also include stopword removal in NLP to remove common words like “the”, “is”, and “and”.
Bag of Words (BoW)
Bag of Words converts text into a vector based on word frequency.
Example sentence:
I love machine learning
The vocabulary might be:
[I, love, machine, learning]
Vector representation:
[1,1,1,1]
But BoW ignores:
- Word order
- Context
- Semantic relationships
For example:
I love machine learning
I hate machine learning
Both sentences would look almost identical in Bag of Words.
One-Hot Encoding
Another early approach was One-Hot Encoding.
Each word in the vocabulary is represented by a vector where only one element is 1 and all others are 0.
Example vocabulary:
[cat, dog, apple, car]
Word vectors:
cat = [1,0,0,0]
dog = [0,1,0,0]
apple = [0,0,1,0]
car = [0,0,0,1]
Problems with one-hot encoding:
- Extremely high dimensional vectors
If your vocabulary has 50,000 words, each word vector has 50,000 dimensions.
- No semantic relationships
cat = [1,0,0,0]
dog = [0,1,0,0]
The distance between “cat” and “dog” is the same as between “cat” and “car”.
Machines cannot recognize that cat and dog are both animals.
TF-IDF Representation
TF-IDF improved on simple frequency counts by measuring the importance of words across documents.
TF-IDF helps identify important keywords in text.
However, TF-IDF still has limitations:
- Words are independent
- No semantic understanding
- Synonyms are treated as different words
Example:
car
automobile
vehicle
TF-IDF treats them as unrelated words.
This is where Word Embeddings in Python become revolutionary.
3. What Are Word Embeddings?
Word embeddings are dense numerical representations of words that capture semantic meaning.
Instead of representing a word using thousands of dimensions, embeddings represent words using compact dense vectors.
Example embedding:
cat = [0.23, -0.11, 0.87, 0.44, -0.19]
dog = [0.25, -0.10, 0.85, 0.41, -0.20]
car = [-0.50, 0.91, -0.12, 0.03, 0.88]
Notice:
- cat and dog vectors are similar
- car vector is very different
This means the model understands that cat and dog share semantic similarity.
Word Embeddings as a Vector Space
Understanding Word Embeddings in Python is essential for anyone learning Natural Language Processing.
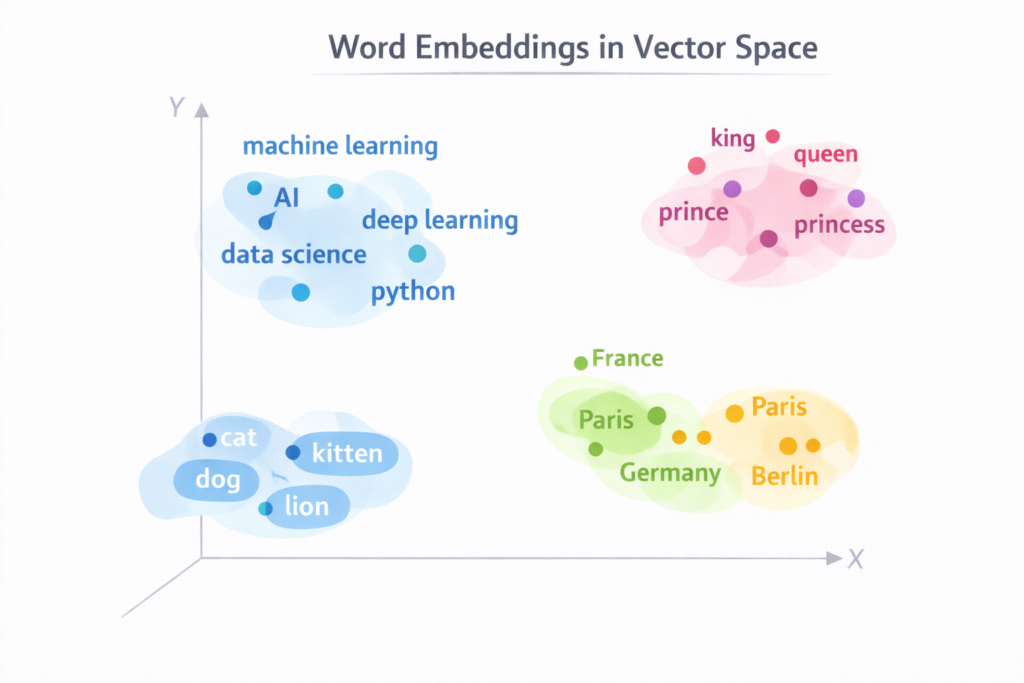
Imagine a huge multi-dimensional map where each word is represented as a point.
Words with similar meanings appear close together in this space.
Example clusters might look like:
Animal cluster:
cat
dog
lion
tiger
Country cluster:
France
Germany
Italy
Spain
Technology cluster:
Python
Java
TensorFlow
PyTorch
This spatial representation allows machines to understand relationships between words.
Dense vs Sparse Vectors
Earlier text representations were sparse vectors.
Example:
[0,0,0,1,0,0,0,0,0,0]
Most values were zero.
Word embeddings use dense vectors.
Example:
[0.21, -0.44, 0.93, 0.17, -0.61]
Advantages of dense vectors:
- Smaller size
- Capture semantic meaning
- Better performance in machine learning models
Most word embeddings use 50 to 300 dimensions.
A common choice is:
300-dimensional embeddings
These are widely used in NLP applications.

4. The Famous Word Vector Arithmetic
One of the most fascinating aspects of word embeddings is vector arithmetic.
Researchers discovered that relationships between words can be represented mathematically.
Example:
King - Man + Woman ≈ Queen
This means:
- Take the vector for king
- Subtract the vector for man
- Add the vector for woman
The result is very close to the vector for queen.
This shows that word embeddings capture semantic relationships such as gender and hierarchy.
Other examples:
Paris - France + Germany ≈ Berlin
walking - walk + run ≈ running
These relationships emerge automatically during training.
5. Why Word Embeddings Are Important in NLP
Word embeddings are used in many NLP applications.
Some examples include:
Sentiment Analysis
Understanding whether a sentence expresses:
- Positive emotion
- Negative emotion
- Neutral sentiment
Machine Translation
Translating text between languages such as:
English → Spanish
English → Urdu
Chatbots
Conversational AI systems rely on word embeddings to understand user input.
Search Engines
Search engines use embeddings to understand semantic similarity between queries and documents.
Recommendation Systems
Word embeddings can help recommend:
- Articles
- Products
- Videos
based on semantic similarity.
6. Popular Word Embedding Algorithms
Several algorithms exist for generating word embeddings.
The most famous ones include:
- Word2Vec
- GloVe
- FastText
In this tutorial we will focus on:
- Word2Vec
- GloVe
These two algorithms are foundational techniques that every NLP engineer should understand.
Even though modern AI models like Transformers and Large Language Models use more advanced embeddings, the concepts behind Word2Vec and GloVe remain extremely important.
7. Introducing Word2Vec
Word2Vec is one of the most influential algorithms in Natural Language Processing.
It was introduced by researchers at Google in 2013.
The main idea behind Word2Vec is simple:
You can understand a word by looking at the words that appear around it.
This idea is summarized by a famous quote from linguist John Firth:
“You shall know a word by the company it keeps.”
Word2Vec learns word meaning by analyzing context.
For example, if the word apple frequently appears near:
fruit
juice
tree
sweet
then the model learns that apple belongs to the fruit category.
In the next section we will explore:
- How Word2Vec actually works
- The CBOW architecture
- The Skip-Gram architecture
and then we will start implementing Word Embeddings in Python using Gensim.
Word2Vec is one of the most popular methods for generating Word Embeddings in Python.
8. How Word2Vec Works
Word2Vec is one of the most important algorithms used to generate Word Embeddings in Python. Instead of counting words like traditional NLP methods, Word2Vec learns word meaning by analyzing context.
The key idea is simple:
Words that appear in similar contexts tend to have similar meanings.
For example, consider the following sentences:
I love machine learning
I love deep learning
I enjoy machine learning
In these sentences:
- love and enjoy appear in similar contexts
- machine learning and deep learning appear in similar contexts
A Word2Vec model learns these patterns automatically and places similar words close together in the vector space.
9. The Two Architectures of Word2Vec
Word2Vec has two main architectures:
- CBOW (Continuous Bag of Words)
- Skip-Gram
Both methods learn word embeddings but use different training strategies.
9.1 Continuous Bag of Words (CBOW)
CBOW predicts a word based on its surrounding context.
Example sentence:
The cat sits on the mat
Suppose the target word is sits.
The context words are:
The cat ___ on the mat
The model uses the surrounding words to predict the missing word.
Input (context words):
["The", "cat", "on", "the", "mat"]
Output:
"sits"
CBOW works well when:
- Training data is large
- Speed is important
Because CBOW averages the context words, it trains faster than Skip-Gram.
9.2 Skip-Gram Model
Skip-Gram works in the opposite way.
Instead of predicting a word from context, it predicts context words from a target word.
Example sentence:
The cat sits on the mat
Target word:
sits
The model predicts:
cat
on
the
Skip-Gram performs better for rare words, which is why it is often preferred in modern NLP tasks.
CBOW vs Skip-Gram
| Feature | CBOW | Skip-Gram |
|---|---|---|
| Training Speed | Faster | Slower |
| Rare Words | Not very good | Better |
| Accuracy | Good | Often better |
| Training Data | Large datasets | Works well with smaller data |
In most NLP projects, Skip-Gram is commonly used because it produces higher-quality embeddings.

10. Implementing Word Embeddings in Python Using Gensim
Now we will implement Word Embeddings in Python using the Gensim library.
Gensim is one of the most popular Python libraries for training Word2Vec models.
10.1 Installing Required Libraries
First install the required Python libraries.
pip install gensim
pip install nltk
pip install numpy
These libraries help us:
- Train Word2Vec models
- Process text data
- Perform numerical operations
10.2 Preparing a Sample Dataset
Before training Word2Vec, we need text data.
Let’s create a small dataset.
sentences = [
["i", "love", "machine", "learning"],
["machine", "learning", "is", "powerful"],
["i", "love", "artificial", "intelligence"],
["deep", "learning", "drives", "ai"],
]
Each sentence is represented as a list of tokens.
This is similar to the tokenization step you learned in earlier NLP tutorials.
Before training a Word2Vec model, the text must be split into tokens using tokenization in Python.
10.3 Training a Word2Vec Model
Now we train a Word2Vec model.
from gensim.models import Word2Vecmodel = Word2Vec(
sentences,
vector_size=100,
window=5,
min_count=1,
workers=4
)
Explanation of parameters:
| Parameter | Meaning |
|---|---|
| vector_size | Dimension of word vectors |
| window | Context window size |
| min_count | Minimum word frequency |
| workers | Number of CPU threads |
The model automatically learns word relationships from the dataset.
10.4 Accessing Word Vectors
After training the model, we can access the vector representation of words.
Example:
vector = model.wv["learning"]
print(vector)
This prints a numerical vector representing the word learning.
Example output:
[0.12, -0.34, 0.78, -0.21, ...]
Each number represents one dimension in the embedding space.
10.5 Finding Similar Words
One powerful feature of Word2Vec is finding similar words.
Example:
model.wv.most_similar("learning")Example output:
[('machine', 0.83),
('deep', 0.79),
('ai', 0.75)]This means the model learned that machine, deep, and AI are related to learning.
This is the core idea behind Word Embeddings in Python.
10.6 Word Vector Similarity
We can also measure similarity between two words.
Example:
similarity = model.wv.similarity("machine", "learning")
print(similarity)Output might look like:
0.78
A higher score means the words are more semantically similar.
11. Visualizing Word Embeddings
Word embeddings are usually 100–300 dimensional vectors, which are difficult to visualize.
To visualize them, we reduce dimensions using PCA (Principal Component Analysis).
Example code:
from sklearn.decomposition import PCA
import matplotlib.pyplot as pltwords = ["machine", "learning", "ai", "deep"]vectors = [model.wv[word] for word in words]pca = PCA(n_components=2)
result = pca.fit_transform(vectors)for i, word in enumerate(words):
plt.scatter(result[i,0], result[i,1])
plt.text(result[i,0], result[i,1], word)plt.show()
This will produce a 2D plot of word vectors.
Words with similar meanings appear closer together.
Visualization helps us understand how Word Embeddings in Python capture semantic relationships.
12. GloVe: Global Vectors for Word Representation
Another powerful method for generating Word Embeddings in Python is GloVe (Global Vectors for Word Representation).
GloVe was developed by researchers at Stanford University and released in 2014. While Word2Vec learns embeddings using prediction-based models, GloVe learns embeddings using global statistical information from a corpus.
The key idea behind GloVe is simple:
Words that frequently appear together in large text corpora should have similar vector representations.
Instead of predicting context words like Word2Vec, GloVe analyzes co-occurrence statistics across the entire dataset.
This allows the algorithm to capture deeper relationships between words.
13. Understanding the Co-Occurrence Matrix
The core concept behind GloVe is the co-occurrence matrix.
A co-occurrence matrix records how often words appear together within a certain context window.
Example corpus:
I love machine learning
Machine learning is powerful
Vocabulary:
I, love, machine, learning, is, powerful
A simplified co-occurrence matrix might look like:
| Word | I | love | machine | learning | is | powerful |
|---|---|---|---|---|---|---|
| I | 0 | 1 | 1 | 0 | 0 | 0 |
| love | 1 | 0 | 1 | 1 | 0 | 0 |
| machine | 1 | 1 | 0 | 2 | 1 | 0 |
| learning | 0 | 1 | 2 | 0 | 1 | 1 |
This matrix captures global word relationships across the entire corpus.
GloVe uses mathematical optimization to convert this matrix into dense vector embeddings.
14. How GloVe Generates Word Embeddings
GloVe works by factorizing the co-occurrence matrix to learn vector representations of words.
The algorithm learns word vectors such that:
- Words appearing in similar contexts have similar vectors
- Word relationships are preserved mathematically
For example, GloVe embeddings can capture relationships like:
king - man + woman ≈ queen
This means semantic relationships are encoded directly in the vector space.
The final output is similar to Word2Vec: each word is represented as a dense vector of numbers.
Example:
king = [0.23, -0.91, 0.45, 0.78 ...]
queen = [0.25, -0.89, 0.47, 0.81 ...]
These vectors can then be used in machine learning models.
15. Word2Vec vs GloVe
Both Word2Vec and GloVe are widely used for creating Word Embeddings in Python, but they use different training strategies.
| Feature | Word2Vec | GloVe |
|---|---|---|
| Training Method | Prediction-based | Count-based |
| Learning Strategy | Local context windows | Global corpus statistics |
| Speed | Fast training | Slightly slower |
| Dataset Size | Works well with large data | Requires large corpus |
| Accuracy | Very strong | Also very strong |
In practice, both methods produce high-quality embeddings, and the choice often depends on the dataset and application.
16. Using Pre-Trained GloVe Embeddings
Training word embeddings from scratch requires large datasets.
Many researchers therefore use pre-trained embeddings that were trained on massive corpora such as:
- Wikipedia
- Common Crawl
- News datasets
Stanford provides publicly available GloVe embeddings trained on billions of words.
These embeddings typically have:
- 50 dimensions
- 100 dimensions
- 200 dimensions
- 300 dimensions
The 300-dimension embeddings are the most commonly used.
17. Downloading GloVe Embeddings
You can download pre-trained GloVe vectors from the Stanford NLP website.
Example datasets include:
glove.6B.50d.txt
glove.6B.100d.txt
glove.6B.300d.txt
Each file contains word vectors for hundreds of thousands of words.
Example line from a GloVe file:
king 0.5045 -0.1762 0.2311 -0.9872 ...
The first value is the word, and the remaining values are the embedding vector.
18. Loading GloVe Embeddings in Python
Now let’s load GloVe embeddings into Python.
Example code:
import numpy as npembeddings = {}with open("glove.6B.100d.txt", encoding="utf8") as f:
for line in f:
values = line.split()
word = values[0]
vector = np.asarray(values[1:], dtype="float32")
embeddings[word] = vectorNow the dictionary embeddings contains vectors for thousands of words.
Example:
vector = embeddings["king"]
print(vector[:10])
Output might look like:
[0.5045 -0.1762 0.2311 -0.9872 ...]
Each word now has a numerical vector representation.
This is a practical way to use Word Embeddings in Python without training a model from scratch.
19. Finding Similar Words with GloVe
We can also compute similarity between words using cosine similarity.
Example code:
from sklearn.metrics.pairwise import cosine_similarityking = embeddings["king"].reshape(1, -1)
queen = embeddings["queen"].reshape(1, -1)similarity = cosine_similarity(king, queen)print(similarity)
Example output:
0.86
This high similarity score shows that king and queen are closely related in the embedding space.
20. Why Pre-Trained Embeddings Are Useful
Using pre-trained embeddings has several advantages.
1. Saves Training Time
Training embeddings from scratch can take hours or days.
Pre-trained embeddings allow you to start immediately.
2. Trained on Massive Datasets
Pre-trained models often use billions of words, making them far more accurate than small custom datasets.
3. Better Performance
Machine learning models often perform better when initialized with pre-trained embeddings.
21. Word Embeddings in Real-World NLP Systems
Today, Word Embeddings in Python are used in many AI systems.
Some common applications include:
Chatbots
Conversational AI systems use embeddings to understand user queries.
Search Engines
Search engines use embeddings to measure semantic similarity between queries and documents.
Document Classification
Embeddings allow models to classify text into categories such as:
- spam detection
- topic classification
- sentiment analysis
Recommendation Systems
Word embeddings can also help recommend:
- articles
- products
- videos
based on semantic similarity.
22. Limitations of Word Embeddings
Although Word Embeddings in Python such as Word2Vec and GloVe revolutionized Natural Language Processing, they still have several limitations.
Understanding these limitations is important when building real-world NLP systems.
22.1 The Polysemy Problem
Polysemy occurs when a word has multiple meanings.
For example:
bank
This word can mean:
- A financial institution
- The side of a river
Traditional word embeddings assign only one vector to each word.
Example:
bank = [0.45, -0.12, 0.88, ...]
This single vector must represent both meanings, which can cause confusion in NLP models.
Example sentences:
I deposited money in the bank
The fisherman sat near the river bank
Word2Vec and GloVe cannot distinguish these meanings effectively.
22.2 Out-of-Vocabulary (OOV) Words
Another major limitation is the Out-of-Vocabulary (OOV) problem.
If a word was not seen during training, the model cannot generate an embedding for it.
Example:
cryptocurrency
If this word was not in the training dataset, the model will not understand it.
This problem becomes significant in:
- social media text
- slang
- newly created words
22.3 Large Data Requirements
Word embedding models require large datasets to learn meaningful relationships.
Training Word2Vec on a very small dataset may produce poor embeddings.
This is why many NLP engineers prefer pre-trained embeddings trained on massive corpora.
22.4 Bias in Word Embeddings
Another important issue is bias in embeddings.
Because word embeddings learn from human-generated text, they can inherit biases present in the training data.
For example, research has shown embeddings sometimes associate:
doctor → male
nurse → female
These biases can affect machine learning systems.
Modern NLP research focuses on bias mitigation techniques to address this problem.
23. FastText: Improving Word Embeddings
To solve some limitations of Word2Vec, researchers at Facebook AI developed FastText.
FastText improves word embeddings by representing words using subword units.
Instead of treating words as single tokens, FastText breaks them into smaller pieces.
Example:
playing
Subword units:
play
lay
ayi
yin
ing
This allows FastText to:
- handle rare words
- generate embeddings for unseen words
- improve performance for morphologically rich languages
FastText is widely used for languages with complex word structures.
24. From Static Embeddings to Contextual Embeddings
Word2Vec and GloVe are called static embeddings.
This means a word always has the same vector, regardless of context.
Example:
bank
Vector representation remains the same in every sentence.
Modern NLP models use contextual embeddings, where the word representation changes depending on context.
Examples of contextual embedding models include:
- BERT
- GPT
- RoBERTa
- T5
These models use transformer architectures to generate context-aware embeddings.
Example:
bank (finance)
bank (river)
Modern models generate different vectors for these meanings.
This significantly improves language understanding.
25. When to Use Word2Vec in 2026
Even though modern NLP models use transformers, Word Embeddings in Python using Word2Vec are still useful in many situations.
Small Machine Learning Projects
If you are building a simple NLP project with traditional machine learning models such as:
- Logistic Regression
- Support Vector Machines
- Random Forest
Word2Vec embeddings work very well.
Low Resource Systems
Transformer models require large computational resources.
Word2Vec embeddings are lightweight and efficient.
They work well in:
- mobile applications
- embedded systems
- real-time NLP pipelines
Feature Engineering
Word embeddings are often used as features in machine learning models.
For example:
Sentence embedding = average of word vectors
This simple technique can perform surprisingly well for classification tasks.
26. Practical Applications of Word Embeddings
Many real-world NLP systems rely on Word Embeddings in Python to process and understand text data.
Today, word embeddings are used in many real-world AI applications.
Some examples include:
1. Sentiment Analysis
Understanding whether text expresses:
- positive emotion
- negative emotion
- neutral sentiment
2. Chatbots and Virtual Assistants
Embeddings help conversational AI systems understand user intent.
Examples include:
- customer support bots
- AI assistants
3. Search Engines
Search engines use embeddings to understand semantic similarity between queries and documents.
For example:
query: best python tutorials
The system can match documents containing:
learn python programming
even though the exact words are different.
4. Document Clustering
Embeddings help group similar documents together.
This is useful in:
- news categorization
- topic discovery
- recommendation systems
27. Summary of Word Embeddings
Let’s quickly recap what we learned in this guide.
Word embeddings convert text into dense numerical vectors that capture semantic meaning.
In summary, Word Embeddings in Python provide a powerful way to convert text into meaningful numerical vectors.
Unlike traditional methods such as:
- Bag of Words
- One-Hot Encoding
- TF-IDF
word embeddings understand relationships between words.
Two of the most popular algorithms are:
Word2Vec
- Prediction-based model
- Uses CBOW and Skip-Gram architectures
GloVe
- Count-based model
- Uses global co-occurrence statistics
These methods allow machines to understand language more effectively.
Although modern NLP models now use contextual embeddings, Word2Vec and GloVe remain fundamental techniques for learning Natural Language Processing.
28. Conclusion
Understanding Word Embeddings in Python is an important milestone for anyone learning Natural Language Processing.
Word embeddings allow machines to move beyond simple word counts and begin understanding the semantic relationships between words.
In this tutorial, we explored:
- Why traditional text representations were limited
- How Word2Vec learns word meaning from context
- How GloVe uses global word statistics
- How to implement embeddings using Python and Gensim
- The limitations of static embeddings
- How modern NLP models evolved from these techniques
If you are learning NLP, mastering word embeddings will give you a strong foundation before moving on to more advanced techniques like transformers and large language models.
Learning Word Embeddings in Python is an important step toward mastering modern Natural Language Processing.
Start experimenting with Word Embeddings in Python, train your own models, and explore how machines learn the meaning of human language.
FAQ: Word Embeddings in Python
1. What are word embeddings in NLP?
Word embeddings are numerical vector representations of words that capture semantic meaning. Instead of representing words as simple tokens, word embeddings map words into dense vectors so that similar words appear closer together in the vector space. This allows machine learning models to understand relationships between words.
2. What is the difference between Word2Vec and GloVe?
Word2Vec is a prediction-based model that learns word embeddings by predicting context words using architectures such as CBOW and Skip-Gram.
GloVe is a count-based model that learns embeddings using global word co-occurrence statistics across the entire corpus.
3. What is the typical dimension of word embeddings?
Most word embeddings use vectors between 50 and 300 dimensions.
A common choice in many NLP applications is 300-dimensional embeddings, which provide a good balance between performance and computational efficiency.
4. Can Word2Vec handle new words?
No. Word2Vec cannot generate embeddings for words that were not seen during training. This is known as the Out-of-Vocabulary (OOV) problem. Models like FastText solve this issue by using subword information.
5. Are Word2Vec and GloVe still useful in 2026?
Yes. Even though modern NLP models like BERT and GPT use contextual embeddings, Word2Vec and GloVe are still useful for:
small NLP projects
feature engineering
lightweight machine learning pipelines
educational understanding of NLP concepts

